Using Machine Learning to Detect Songs Produced by Jack Antonoff
It’s been 17 years since I last did anything in the AI/ML space. Back then, it was as an undergrad taking a “Projects in Artificial Intelligence” class using genetic algorithms to make an app that dynamically generated melodies over chord progressions. With announcements of ground-breaking advances in neural networks coming out seemingly daily for the past few months, I knew I needed to find some time to better understand what’s been going on in all those years. So I requested a big chunk of time off work, and started going through the fast.ai course.
I’ve only just finished the first lesson so far, but thanks to how approachable fast.ai makes its materials, I’ve managed to throw together something interesting.
The Idea
Last month, @calebgamman put up a viral video of him guessing which songs off Taylor Swift’s new album, Midnights, were produced by Jack Antonoff. If you haven’t already, you should take a moment to watch it here.
(Caleb’s YouTube channel is also worth checking out. He’s got a bunch of high-quality videos, including one on his thoughts on AI, and a criminally low subscriber count.)
I was very skeptical it would work at all, but figured it might be fun to see if I could use what I learned from the first chapter (and some Googling) to train a neural network to do something similar. I’m in absolute disbelief that it actually turned out to work decently and didn’t require a huge training set nor much coding at all.
The Approach
The implementation turned out to be straight-forward: take the audio files, turn them into spectrograms, and then use those to “fine tune” an existing, pre-trained computer vision model.
To start, I went through Taylor Swift’s album pages on Wikipedia to find songs produced by Jack Antonoff. Antonoff has produced music for a ton of other artists, including The 1975, Lorde, and Lana del Rey, but I decided to limit the training set to just Taylor Swift songs, since I wasn’t sure what would happen if I started throwing in other artists. I also grabbed URLs to song previews for each song and put everything in a CSV file. Here’s a sample of its structure:
Producer,Artist,Title,URL
Jack Antonoff,Taylor Swift,Out of the Woods,https://audio-ssl.itunes.apple.com/itunes-assets/AudioPreview115/v4/86/37/dd/8637dd40-bbbd-ed09-9c0d-cc802f5cfd21/mzaf_10076581349863730065.plus.aac.ep.m4a
Jack Antonoff,Taylor Swift,Cruel Summer,https://audio-ssl.itunes.apple.com/itunes-assets/AudioPreview112/v4/85/8e/b9/858eb9a3-e75a-363a-4049-71d654a4104c/mzaf_4981758308159811037.plus.aac.ep.m4a
I ended up with 85 songs to use for training, 39 produced by Antonoff and 46 produced by others. Next, I wrote a Python script to parse the CSV, download the audio previews, and generate a spectrogram of the first 30 seconds of each audio preview:
import re
import csv
import librosa
import numpy as np
import matplotlib.pyplot as plt
import librosa.display
from urllib.request import urlretrieve
def clean_name(name):
cleaned = re.sub('[^a-zA-Z0-9 \n\.]', '', name.lower())
return cleaned.replace(" ", "_")
def plot(filename, outname):
print(f'Loading {filename}')
y, sr = librosa.load(filename, duration=30.0)
fig, ax = plt.subplots()
plt.axis('off')
S = librosa.feature.melspectrogram(y=y, sr=sr)
S_dB = librosa.power_to_db(S, ref=np.max)
librosa.display.specshow(S_dB, sr=sr, x_axis='time', y_axis='mel', ax=ax)
fig.savefig(outname, bbox_inches = 'tight', pad_inches = 0)
plt.close(fig)
def download_files(data_file):
with open(data_file, newline='') as csvfile:
csvreader = csv.DictReader(csvfile)
for row in csvreader:
producer = clean_name(row['Producer'])
artist = clean_name(row['Artist'])
title = clean_name(row['Title'])
url = row['URL']
filename = f'{producer}-{artist}-{title}'
print(f'Downloading {filename}')
urlretrieve(url, f'./originals/{filename}.m4a')
print(f'Generating spectrograms for {filename}')
plot(f'./originals/{filename}.m4a', f'./spectrograms/{filename}.png')
download_files('data.csv')
I spent a bunch of time trying to figure out how to generate and save spectrogram images. A lot of tutorials I found online used the fastaudio library, but that had version conflicts with the fastai libraries, so I decided to switch to using librosa instead. Eventually, I got everything working and saving images that looked like this:
From there, I moved over to a Jupyter notebook on Kaggle to do the actual training since my four-year-old laptop wasn’t up for the task. I zipped up the images and uploaded them as a Kaggle dataset and wrote some basic code to fine tune a vision model:
from fastai.vision.all import *
input_path = '/kaggle/input/antonoff-detector/spectograms'
def is_produced_by_jack(x):
return x.startswith('jack_antonoff-')
dls = ImageDataLoaders.from_name_func(input_path,
get_image_files(input_path),
valid_pct=0.2,
seed=42,
label_func=is_produced_by_jack,
bs=16)
learn = vision_learner(dls, resnet18, loss_func=CrossEntropyLossFlat(), metrics=[accuracy])
callbacks = [ReduceLROnPlateau(monitor='valid_loss', min_delta=0.1, patience=2),
EarlyStoppingCallback(monitor='valid_loss', min_delta=0.05, patience=4)]
learn.fine_tune(20, wd=0.1, cbs=callbacks)
Finally, I tried the model out on some song spectrograms that I had set aside for testing–ones that the model had never seen before—and was surprised to find it actually did a good job! 75% of the time, it was able to correctly identify if a Taylor Swift song was produced by Jack Antonoff or not. I’m honestly amazed at how well it did with such little work.
From there, I tried a few tweaks to see if I could improve the accuracy:
- Instead of using the
resnet18architecture, I triedresnet34. Unfortunately, that didn’t help and resulted in decreased accuracy. I trieddensenet161as well, since I’d seen an article about how it performed better thanresnet18on audio spectrograms, but I kept hitting GPU limits in Kaggle and wasn’t able to run it at all. - I tried different batch sizes: 8, 16, and 32, but settled on 16.
- I tried some light data augmentation using MixUp, but that didn’t help.
- The audio previews were about a minute long, and I was only taking the first 30 seconds, so I figured I might be able to increase the accuracy by making spectrograms of the second 30 seconds of the songs and adding those to the training set as well. This helped a little, bringing the accuracy up to 78% against never-seen-before test data. For this model, I also tried to see how well it would do against songs not by Taylor Swift (some produced by Antonoff and some by others), but came back with only 54% accuracy.
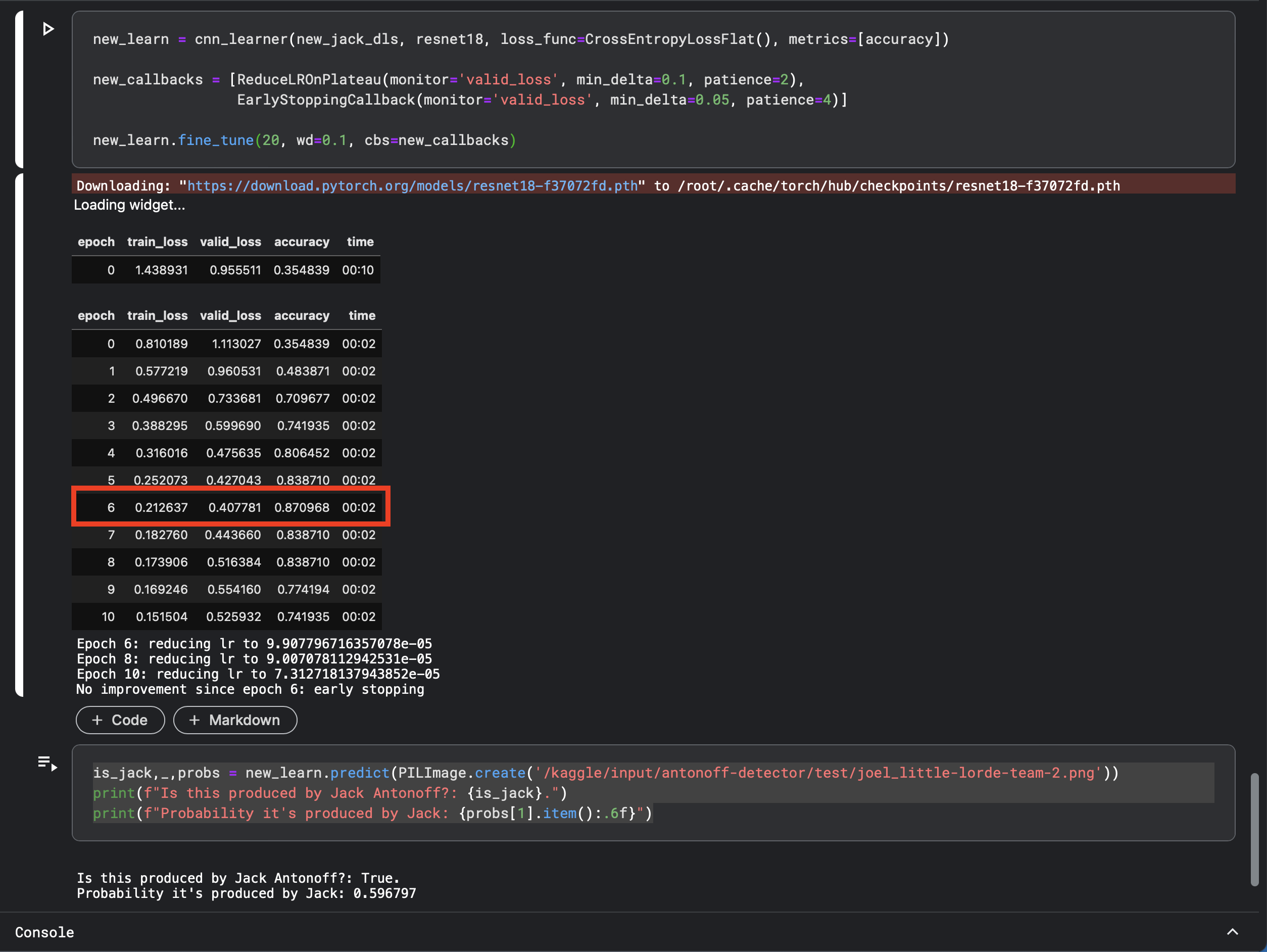
While doing all this, I was surprised to find that training models isn’t deterministic—different training runs result in different levels of accuracy. For example, here I train the model and get an accuracy of 87%:
And then immediately run it again—with no other changes—and get an accuracy of 77%:
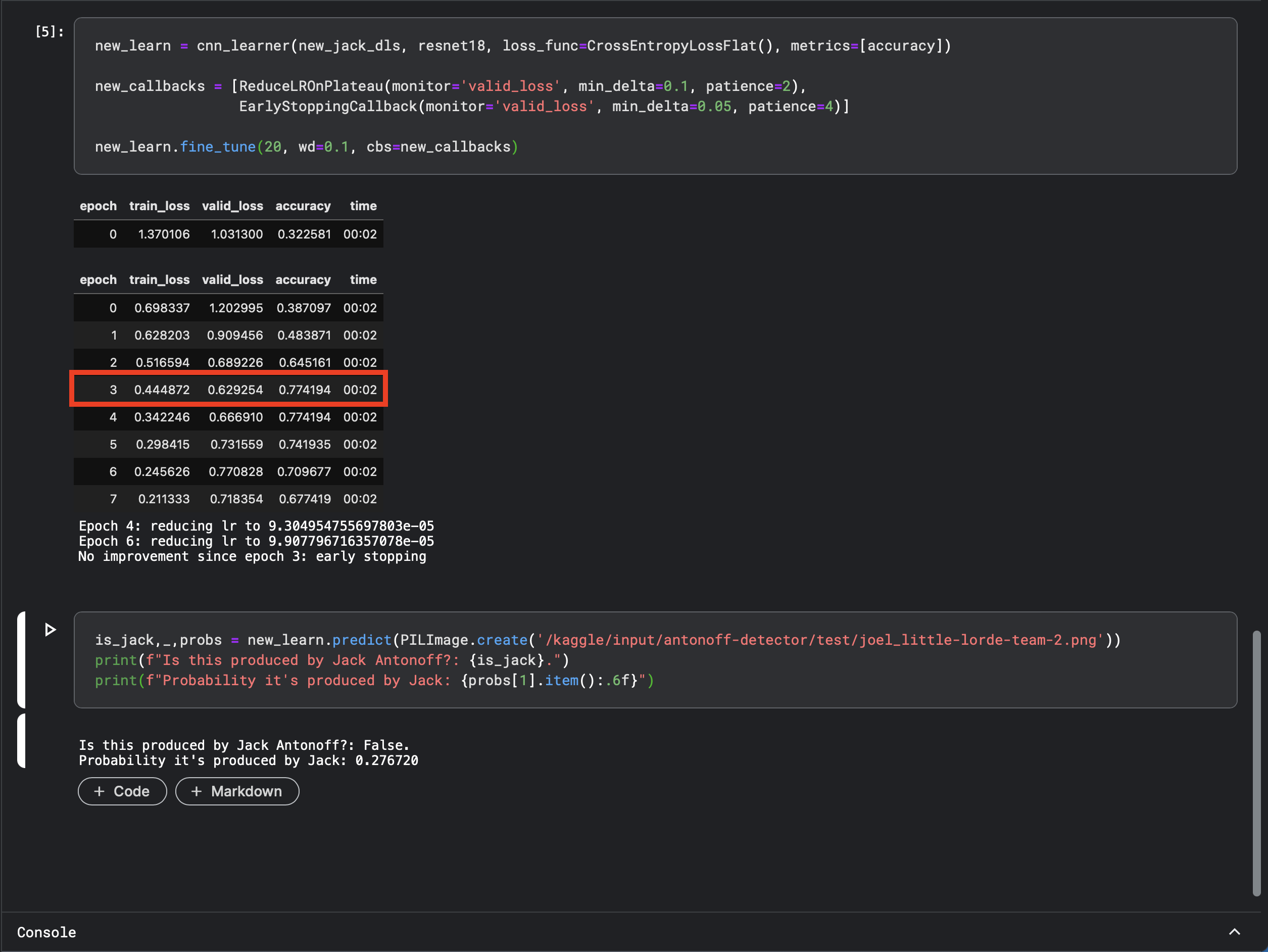
Even stranger, the model with 87% accuracy was wrong when I asked it about a Lorde song produced by Joel Little, while the model with the 77% accuracy correctly identitified that it wasn’t produced by Antonoff.
In retrospect this non-deterministic model generation makes sense, since the neural network is “discovering” a set of weights that fit the problem space, and with a small training set there could be multiple weights that work, but it still feels…weird. And I have no idea why the model with lower accuracy gave a better answer for the Lorde test case.
Final Thoughts
Overall, I wasn’t prepared for how “fuzzy” things would be. I thought there’d be a more precise way to determine which architecture and parameter values to use, but it ended up being a lot of “try it and see how it works”. Will using MixUp improve accuracy? Maybe? Try it and find out! What batch size should I be using? Small, but not too small. How small? Try a few and see!
I still don’t know enough to make any bold predictions about AI, but I’m having fun with what I’m learning so far and looking forward to the rest of the course.